Architecture
llm-connector is designed to provide a unified, type-safe interface for various LLM providers while abstracting over protocol differences.
Core Design Principles
- Unified Interface — A single
LlmClientthat works with any backend provider. - Protocol / Provider Separation —
Protocolhandles request/response format;Providerhandles HTTP transport. - Explicit Configuration — All constructors require explicit
base_url; no hidden defaults. Simplifies multi-tenant routing and proxy scenarios. - Proxy / Middleware Ready — Protocol request types implement both
SerializeandDeserialize, so incoming wire-format bodies can be parsed and forwarded without loss.
Layer Overview
LlmClient
└── Provider (trait)
├── GenericProvider<P: Protocol> ← most providers
│ ├── Protocol::build_request() → serializes ChatRequest → wire format
│ ├── HttpClient → sends HTTP, handles retries
│ └── Protocol::parse_response() → deserializes wire format → ChatResponse
├── OllamaProvider ← Ollama-specific streaming
├── TencentProvider ← TC3-HMAC-SHA256 signing
└── MockProvider ← testing🏗️ Protocol Layer Architecture
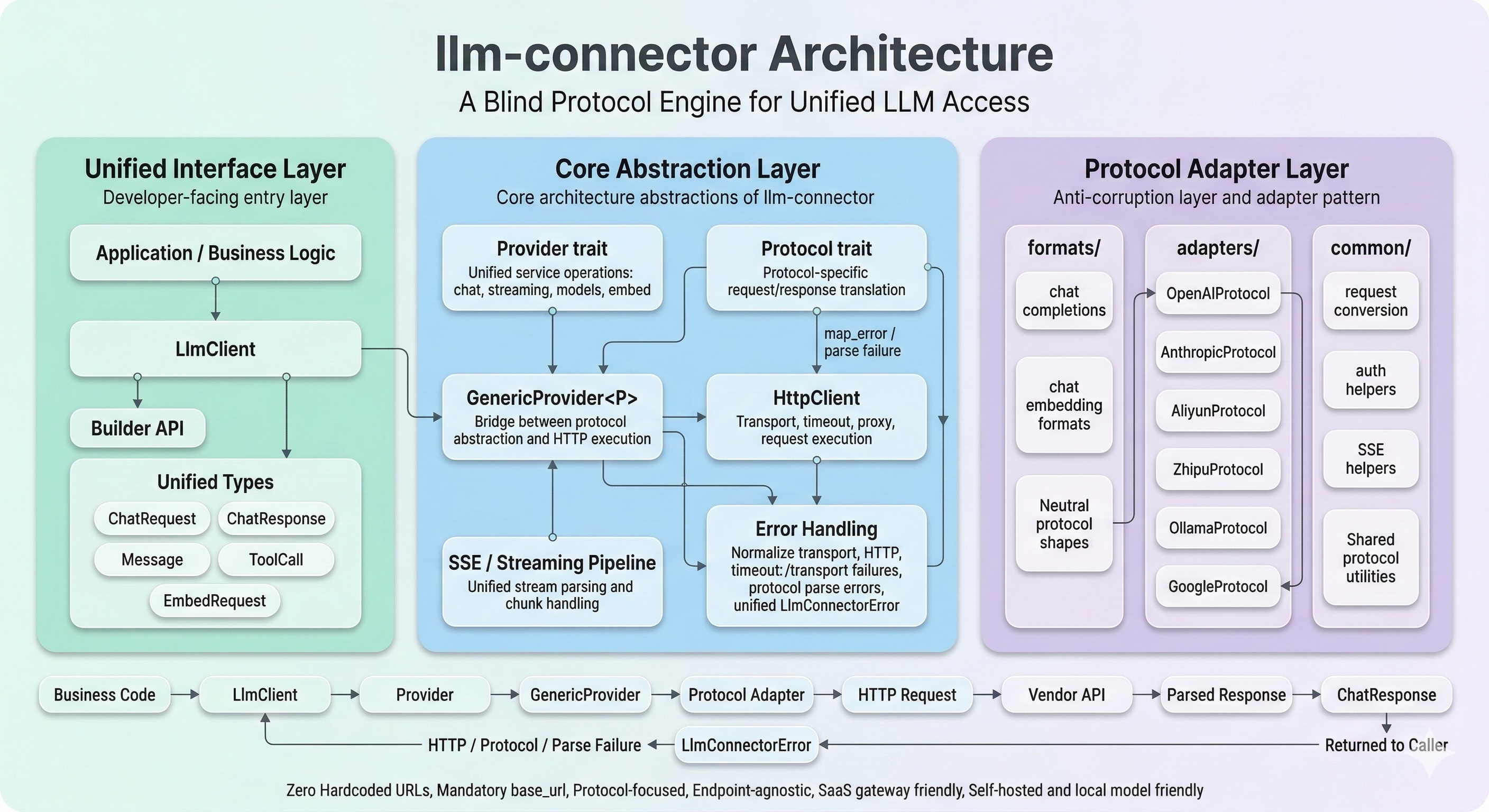
The src/protocols/ module is a strict Anti-Corruption Layer (ACL) built with the Adapter Pattern. It isolates your application from vendor-specific API drift by enforcing a single internal contract (ChatRequest/ChatResponse) and translating it into each vendor's JSON dialect.
formats/: Protocol-agnostic structures (chat completions / embeddings) used as internal neutral shapes.adapters/: Vendor dialect translators that map unified requests to vendor payloads and map vendor responses back.common/: Shared conversion utilities, auth helpers, and SSE/stream tooling.
Per-Request Overrides (Multi-Tenant / Gateway)
Override API key, base URL, and headers per request without creating a new client:
let client = LlmClient::openai("default-key", "https://api.openai.com/v1")?;
let request = ChatRequest::new("gpt-4o")
.add_message(Message::user("Hello"))
.with_api_key("tenant-specific-key")
.with_base_url("https://proxy.example.com/v1")
.with_header("X-Trace-Id", "trace-123");
let response = client.chat(&request).await?;with_api_key: Overrides bothAuthorization: Bearerandx-api-key.with_base_url: Uses a different base URL for just this request.with_header: Custom headers injected alongside provider defaults.
Supported for all providers backed by GenericProvider (OpenAI, Anthropic, DeepSeek, Moonshot, Volcengine, etc.).
Unified Response Types
All providers normalize to the same output types:
pub struct ChatResponse {
pub content: String,
pub reasoning_content: Option<String>, // DeepSeek R1, Moonshot Thinking, Gemini Thinking
pub tool_calls: Option<Vec<ToolCall>>,
pub usage: Option<Usage>,
// ...
}
pub struct StreamingResponse {
pub content: Option<String>,
pub reasoning_content: Option<String>,
pub tool_calls: Option<Vec<ToolCall>>,
pub usage: Option<Usage>,
// ...
}Multi-Modal Support
Multi-modal inputs are handled via the MessageBlock enum:
pub enum MessageBlock {
Text { text: String },
Image { source: ImageSource }, // Base64
ImageUrl { image_url: ImageUrl }, // URL
Document { source: DocumentSource },// PDF etc. (Anthropic, Google)
}- OpenAI:
content: [{type: "text"}, {type: "image_url"}] - Anthropic:
content: [{type: "text"}, {type: "image"}] - Google:
parts: [{text: "..."}, {inlineData: {...}}]
Streaming Architecture
- Enabled via the
streamingfeature (default on). - Uses
reqwest+ SSE/JSONL parsing. - Each provider implements
parse_stream_response. - Normalized to a unified
StreamingResponsestream. - Reasoning content (
reasoning_content) extracted from provider-specific delta fields.
Reverse Proxy / Middleware Support
All protocol request structs (OpenAIRequest, AnthropicRequest, GoogleRequest, etc.) derive both Serialize and Deserialize. This means a proxy or middleware can:
// Deserialize incoming wire-format body
let req: OpenAIRequest = serde_json::from_str(&body)?;
// Inspect, modify, log...
// Re-serialize and forward
let forwarded = serde_json::to_string(&req)?;